


“And yet it moves.” Galileo’s whispered defiance captured a paradox that has animated science for four centuries: belief colliding with observation, dogma yielding—slowly, sometimes painfully—to empiricism. Critical care has lived this story in fast-forward. Today’s trials are built on yesterday’s disappointments, just as tomorrow’s practice will be chiselled by what we learn today. We test, we are humbled, we refine—and we test again. The cosmos does not blink; the heavens keep their counsel. But the data, when coaxed carefully, will speak.
From catechism to calculus: how iterative trials reshaped sepsis resuscitation
Septic shock resuscitation has oscillated between credos. In 2001, the single-centre Early Goal-Directed Therapy (EGDT) study suggested a dramatic survival benefit with a tightly scripted haemodynamic algorithm, catalysing a global movement toward protocolised early care.1 A decade later, three large multicentre RCTs—ProCESS, ARISE and ProMISe—each failed to reproduce mortality advantages for EGDT over contemporary usual care, collectively reframing the field and revealing how secular improvements, early antibiotics and rapid source control had narrowed any residual margin for protocol benefit.2,3,4
Fluids—the primordial reflex in shock—also lost their uncontested status. In the CLASSIC trial, restrictive versus standard fluid strategies in early (< 12 hours) septic shock showed no mortality benefit.5 In the CLOVERS trial, in very early (< 4 hours) sepsis with hypotension, an early fluid restrictive strategy, combined with earlier vasopressors, was likewise neutral for survival.6 In children with severe infection in low-resource settings (FEAST), rapid fluid boluses increased mortality, a sobering reminder that physiology and context matter.7 Moving past the issue of fluids, even the question of when to start the vasopressor—earlier rather than later—produced only modest, mixed signals for clinical benefit (CENSER).8
Fluid type has been similarly contested. Pragmatic trials in ED and ICU (SALT-ED, SMART) suggested balanced crystalloids may reduce some kidney-related events compared with saline,9,10 but two large RCTs addressing fluid resuscitation in the ICU (BaSICS, PLUS) were neutral for mortality and most major outcomes.11,12 ESICM’s 2024 guideline now conditionally recommends balanced crystalloids as the default resuscitation fluid for most critically ill adults, including sepsis.13
Vasopressor questions—drug and dose—have also been incrementally resolved. Noradrenaline emerged as the preferred first-line agent over dopamine,14 higher versus lower MAP targets did not improve survival overall (SEPSISPAM; 65 Trial),15,16 adding vasopressin to noradrenaline was neutral for primary endpoints (VASST) and early vasopressin versus noradrenaline in septic shock did not improve 28-day mortality (VANISH),17,18 while angiotensin II addressed a rescue niche (ATHOS-3).19
Viewed together, these trials do not indict resuscitation per se; they indict uniform resuscitation. Their null results invite a precision approach: identify the patients in whom a specific physiology predominates and individualise the response. That concept flickered in ANDROMEDA-SHOCK (2019), where targeting capillary refill time (CRT) rather than lactate yielded faster organ-dysfunction recovery, less fluid administration and a probabilistic signal for survival benefit in Bayesian analyses.20,21 That signal—tentative but tantalising—set the stage for a larger, more rigorous test of a personalised, physiology-anchored strategy.
Premise: is septic shock a hypoperfused state, and can we restore it?
Septic shock often appears as a macrocirculatory haemodynamic problem—relative or absolute hypovolaemia, vasoplegia, myocardial dysfunction—before later more obviously impacting the microcirculation. Multiple lines of evidence confirm that peripheral perfusion is frequently—though not universally—abnormal and that its improvement tracks clinical recovery. Capillary refill time correlates with global perfusion and clinical outcome; in patients with septic shock, a prolonged CRT was associated with higher SOFA scores, elevated lactate concentrations and increased 28-day mortality, supporting its role as a bedside marker of organ dysfunction and risk of death.22
The ANDROMEDA-SHOCK-2 (AS-2) algorithm: physiology first
ANDROMEDA-SHOCK-2 scaled the original concept into a personalised, tiered strategy that begins with CRT and then interrogates simple haemodynamic signals to infer the dominant physiology.23,24 The protocol’s four pillars were (1) CRT normalisation as the resuscitation target; (2) early identification of haemodynamic pattern—persistent hypovolaemia, vasoplegia or cardiac dysfunction—using pulse pressure (PP), diastolic arterial pressure (DAP) and focused echocardiography; (3) systematic testing of fluid responsiveness (FR) before any fluid bolus; and (4) two reversible “tests”: a 1-hour higher mean arterial pressure (MAP) target and a 1-hour fixed low-dose dobutamine trial, each continued only if CRT improved.23
Are the monitoring components valid? CRT has face validity and prognostic and monitoring utility in septic shock,22 and in the original trial, targeting CRT improved multiple clinically relevant endpoints.20 Fluid-responsiveness testing is well supported mechanistically and operationally: passive leg raising and dynamic preload indices identify patients likely to augment stroke volume with fluid, limiting unnecessary boluses.25 PP and DAP are physiologically sensible integrators—narrow PP suggests low stroke volume; low DAP suggests vasoplegia and impaired coronary perfusion pressure—though their prospective validation as decision rules in sepsis has been limited; AS-2 prospectively embeds them in a response-adaptive framework rather than treating them as static thresholds.23 Bedside echocardiography can rapidly identify gross ventricular dysfunction and major causes of FR-negativity; while RCTs proving outcome benefit from echo-guided resuscitation alone are lacking, the tool is important for physiological classification.23
And the interventions? Noradrenaline remains first-line,14 higher versus lower MAP targets confer no overall survival benefit though may matter in selected chronic hypertensive phenotypes (SEPSISPAM; 65 Trial),15,16 adding vasopressin early was neutral overall,17,18 and angiotensin II may rescue refractory vasoplegia.19 Fluids beyond initial resuscitation add risk without certain benefit in contemporary care,5,6 and balanced crystalloid versus saline choices may not matter at the relatively low volumes used in contemporary trials.11,12 Dobutamine is a useful test-drug when frank cardiac dysfunction is suspected, but trials aimed at “supranormal” oxygen delivery—often using dobutamine—failed to improve survival, underscoring the importance of discontinuing inotropes if perfusion does not clearly improve.26,27
What did AS-2 find?
Design and primary analysis. AS-2 was an investigator-initiated, international, open-label RCT across 86 ICUs in 19 countries, randomising 1467 patients within 4 h of septic shock diagnosis to CRT-personalised haemodynamic resuscitation (CRT-PHR) versus usual care.23 The primary endpoint was a hierarchical composite of 28-day mortality, duration of organ (vital) support (vasoactives, invasive ventilation, kidney replacement therapy) and hospital length of stay, analysed with a win ratio (WR). The CRT-PHR group registered 131,131 wins (48.9%) vs 112,787 (42.1%) in usual care for an overall WR 1.16 (95% CI, 1.02–1.33; p=0.04).23
Mortality and high-level outcomes. 28-day mortality was essentially identical (HR 0.99; 95% CI, 0.81–1.21; p=0.91).23 All-cause 90-day mortality was also similar: 231/719 (32.1%) vs 247/744 (33.2%); HR 0.93 (95% CI, 0.78–1.11).
Duration of organ support. Within 28 days, durations were lower with CRT-PHR for vasopressors (mean difference −0.95 days; 95% CI, −1.58 to −0.34), invasive ventilation (−0.82 days; 95% CI, −1.55 to −0.11) and renal replacement therapy (−0.45 days; 95% CI, −0.89 to −0.07). The composite “vital-support days” decreased by −1.31 days (95% CI, −2.05 to −0.56). The proportion of patients receiving organ support was similar at key time points, but with small directional differences: at 6 h, vasopressors 94.9% vs 91.6%; invasive ventilation 47.5% vs 47.1%; RRT 6.2% vs 5.7%; at 24 h, vasopressors 80.7% vs 76.4%; ventilation 40.6% vs 41.6%; RRT 8.8% vs 9.0%; at any time during hospitalisation, vasopressors 100% vs 100%, ventilation 55.3% vs 55.6%, RRT 15.1% vs 18.7%, respectively (CRT-PHR vs usual care).23
Length of Stays. Lengths of stay were numerically shorter in the intervention arm; the ICU difference was statistically significant (−1.02 days; 95% CI, −1.82 to −0.23), whereas the hospital difference was not (−2.11 days; 95% CI, −4.62 to 0.39).23
Mechanistic breadcrumbs. CRT normalised more often and earlier with CRT-PHR: by 6 h, 577/679 (85.0%) vs 422/684 (61.7%); the advantage persisted at 24 h (83.4% vs 74.8%), 48 h (87.3% vs 80.6%) and 72 h (87.9% vs 86.0%). Resuscitation fluid volumes were modestly lower in the intervention arm at 6 h (mean difference −251 mL) and 24 h (−327 mL); CVP was lower at 6 h (mean difference −0.59 mmHg), and ScvO2 slightly higher (+1.9 %), suggesting a profile of limited fluid exposure, preserved venous pressures and rapid peripheral reperfusion, although it could equally be argued these differences were clinically minimal.23
Was the win-ratio the right hypothesis test—and what would a “conventional” analysis show?
A hierarchical composite prioritises what matters most (death), while preserving sensitivity to clinically weighty morbidity (organ support) among survivors. The WR has gained traction where mortality alone is underpowered to detect meaningful global benefit.28
In AS-2, had 28-day mortality been the sole primary outcome, the result would be inconclusive (HR 0.99; 95% CI 0.81–1.21; p = 0.91), with confidence intervals encompassing both potential benefit and harm.23 For trials which fail to meet the prespecified primary outcome, secondary endpoints, unless robustly controlled for multiplicity, are considered hypothesis-generating rather than confirmatory.29 But the pre-specified hierarchical composite, analysed by WR, was positive. A Bayesian lens helps reconcile these perspectives: using AI (outlined below), with a non-informative prior, the posterior probability that CRT-PHR reduced 90-day mortality is modest but non-trivial, whereas the posterior probabilities that CRT-PHR reduced vasopressor, ventilation and RRT durations are very high under normal-likelihood approximations. By contrast, the Bayesian re-analysis of the original ANDROMEDA-SHOCK trial found high posterior probabilities of mortality benefit for CRT-targeted care using sceptical and enthusiastic priors—reminding us that prior evidence and choice of estimand matter when death alone is influenced by many co-interventions.21
What, mechanistically, might have shortened organ-support time?
Clues lie in the early signal path. The CRT-PHR group normalised CRT faster (85.0% vs 61.7% at 6 h), did so with slightly less fluid by 6 and 24 h, and had (minimally) lower CVP at 6 h. This profile plausibly reduces pulmonary oedema risk and right-sided congestion (shortening ventilation), minimises renal venous congestion (shortening RRT exposure), and allows earlier pressor weans once perfusion is restored. Importantly, the number of patients on support at 6 h and 24 h was broadly similar between arms—e.g., ventilation 47.5% vs 47.1% at 6 h; RRT 6.2% vs 5.7% at 6 h; vasopressors 94.9% vs 91.6% at 6 h—but their durations diverged thereafter. That pattern is consistent with faster readiness for de-escalation rather than prevention of initial organ failure.23
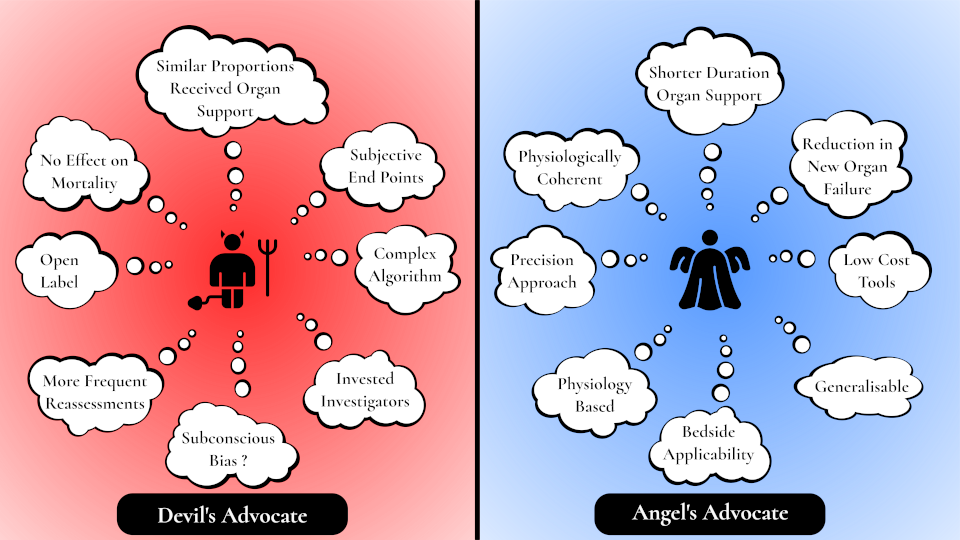
Figure 1. Devil's and Angel's Advocates
Devil’s advocate: could an open-label design bias organ-support durations?
Open-label trials that use duration-of-support endpoints without formal stopping rules risk subtle behavioural drift. Clinicians enthused by a protocol may reassess more frequently, push weans earlier, or accept smaller safety margins. The AS-2 investigators acknowledge this limitation explicitly: extubation and vasopressor discontinuation were not adjudicated and followed local practice.23 Mortality did not differ, numbers receiving support at fixed timepoints were similar, and hospital stay was only modestly shorter—features that invite scepticism that the algorithm truly transformed physiology rather than nudged practice patterns.
Analogous concerns have surfaced elsewhere: paired awakening-and-breathing protocols accelerate ventilator liberation in open-label settings,34 as do nonsedation/light-sedation strategies (NONSEDA),35 while oxygenation trials show how protocolised reassessment alone can move process metrics without clear mortality shifts (ICU-ROX).36
Three further observations may sustain a sceptical reading. First, the fluid separation achieved by AS-2 in the first 6–24 h (≈−250 to −330 mL) is relatively small and sits within a literature where substantially larger, strategy-driven separations were mortality-neutral—for example, restrictive versus standard in CLASSIC and early restrictive versus liberal in CLOVERS; a physiology-guided trial (FRESH) reduced positive fluid balance and a composite of new ventilation or RRT but not death.5,6,30
Second, renal-replacement-therapy timing trials (STARRT-AKI, AKIKI, IDEAL-ICU) illustrate how protocolised criteria strongly shape organ-support exposure; without them, practice variance may dominate.31,32,33,
Third, the intervention arm mandated hourly CRT checks and structured reassessment—more “eyes on the patient”—which could plausibly encourage earlier weaning even without major physiological change.
Angel’s advocate: what AS-2 advances
First, AS-2 extends and strengthens the original ANDROMEDA-SHOCK signal by embedding CRT within a personalisation scaffold—and shows that this approach can reduce time on organ support at scale across 19 countries.23
Second, it operationalises heterogeneity of treatment effect at the bedside. Rather than randomising “more” versus “less” of a single therapy, it uses simple signals to aim fluid to the FR-positive, vasopressors to vasoplegia (low DAP), and inotrope only when cardiac dysfunction seems dominant—then turns each knob off when CRT fails to respond. That is precision medicine, rendered pragmatic.
Third, the effect transcends behaviour-sensitive endpoints. Objective, non-adjudication-dependent signals moved: the total SOFA score declined faster over days 1–7 with CRT-PHR (estimated daily decrease −0.69 vs −0.62; p=0.025), and among patients not on RRT at baseline, new RRT starts were fewer with CRT-PHR (12.0% vs 16.2%; absolute −4.2 percentage points). These point to less new organ dysfunction, not merely faster de-escalation.23
Fourth, both groups received the same core therapies—just at slightly different doses and timing. Within 6–24 h the CRT-PHR arm received ~250–330 mL less crystalloid; noradrenaline doses were similar (6-h mean 0.28 vs 0.27 μg/kg/min), and dobutamine was used more often in CRT-PHR (12.3% vs 5.3% within 6 h), predominantly as a time-limited 5 μg/kg/min “test” continued only if CRT improved—underscoring that the signal derives from personalised titration rather than the introduction of novel agents.23
Fifth, why fluid-strategy RCTs don’t refute AS-2. Trials such as CLASSIC and CLOVERS randomised uniform targets (more vs less fluid) across heterogeneous phenotypes and were mortality-neutral; by contrast, AS-2 personalises fluids via FR-testing and CRT-anchored stopping, and personalises vasoactive/inotropic “tests” with continuation only when CRT responds—making one-size-fits-all comparisons a poor surrogate for a response-adaptive, phenotype-directed strategy.5,6
Finally, the trial is an object lesson in feasibility and equity. It was investigator-generated, multinational, and led from Latin America with collaboration across Europe, Asia and the Middle East. It used low-cost tools (a microscope slide, a stopwatch, and blood pressure monitoring, invasive or non-invasive) and trained clinicians to apply a disciplined algorithm. In an era of strained capacity, a strategy that shortens organ-support exposure—even without a clear survival gain—has tangible implications for bed capacity, ventilator availability and dialysis resources. The analysis recognises that mortality is not the sole arbiter of patient-centred benefit; the WR gives clinical priority to lives saved but still captures morbidity averted among survivors.28
What do we do on Monday?
Proponents will reasonably argue that AS-2, like Galileo’s telescope, sharpens our view. The approach is low-cost, physiologically coherent, and now supported by a large RCT showing less time on organ support without apparent harm. Expect early adopters to implement CRT-PHR—especially the discipline of frequent reassessment, FR-testing before fluids and rapid de-escalation when CRT fails to improve.
Critics will equally note that mortality and fixed-timepoint organ-support proportions were similar, and that the composite result could be vulnerable to behavioural biases in an unblinded setting. They will question whether complex algorithms are necessary to achieve the real driver—more frequent, structured reassessment—and whether individual components without strong evidence should be prescribed widely.
Perhaps the synthesis is this: belief galvanises action, but method restrains it. The heavens taught Galileo that the Earth was not the centre of the universe; AS-2 reminds us that it is not the variable but the patient who lies at the centre, each measurement merely a satellite orbiting their physiology. If we approach resuscitation as AS-2 suggests—observe, test, intervene, reassess—then CRT, like a star, is not the destination but a guide for the journey. The voyage of precision resuscitation continues, steered now by a new light in the sky.
Faith, evidence, and the stars.
References
- Rivers E, Nguyen B, Havstad S, et al. Early goal-directed therapy in the treatment of severe sepsis and septic shock. N Engl J Med. 2001;345:1368-1377
- Yealy DM, Kellum JA, Huang DT, et al; ProCESS Investigators. A randomized trial of protocol-based care for early septic shock. N Engl J Med. 2014;370:1683-1693
- ARISE Investigators; ANZICS Clinical Trials Group. Goal-directed resuscitation for patients with early septic shock. N Engl J Med. 2014;371:1496-1506
- Mouncey PR, Osborn TM, Power GS, et al; ProMISe Trial Investigators. Trial of early, goal-directed resuscitation for septic shock. N Engl J Med. 2015;372:1301-1311
- Meyhoff TS, Hjortrup PB, Møller MH, et al; CLASSIC Trial Group. Restriction of intravenous fluid in ICU patients with septic shock. N Engl J Med. 2022;386:2459-2470
- National Heart, Lung, and Blood Institute PETAL Clinical Trials Network. Early restrictive or liberal fluid management for sepsis-induced hypotension (CLOVERS). N Engl J Med. 2023;388:499-510
- Maitland K, Kiguli S, Opoka RO, et al; FEAST Trial Group. Mortality after fluid bolus in African children with severe infection. N Engl J Med. 2011;364:2483-2495
- Permpikul C, Tongyoo S, Viarasilpa T, et al. Early use of norepinephrine in septic shock (CENSER). Am J Respir Crit Care Med. 2019;199:1097-1105
- Self WH, Semler MW, Wanderer JP, et al; SALT-ED Investigators. Balanced crystalloids versus saline in non-critically ill adults. N Engl J Med. 2018;378:819-828
- Semler MW, Self WH, Wanderer JP, et al; SMART Investigators. Balanced crystalloids versus saline in critically ill adults. N Engl J Med. 2018;378:829-839
- Zampieri FG, Machado FR, Biondi RS, et al; BaSICS Investigators. Effect of intravenous fluid treatment with a balanced solution vs 0.9% saline on 90-day mortality in critically ill patients. JAMA. 2021;326:818-829
- Finfer S, Micallef S, Hammond N, et al. Balanced multielectrolyte solution versus saline in critically ill adults (PLUS). N Engl J Med. 2022;386:1909-1920
- Arabi YM, Belley-Cote E, Carsetti A, et al. ESICM clinical practice guideline on fluid therapy in adult critically ill patients—Part 1: choice of resuscitation fluids. Intensive Care Med. 2024;50:813-831
- De Backer D, Biston P, Devriendt J, et al; SOAP II Investigators. Comparison of dopamine and norepinephrine in the treatment of shock. N Engl J Med. 2010;362:779-789
- Asfar P, Meziani F, Hamel J-F, et al; SEPSISPAM Investigators. High versus low blood-pressure target in septic shock. N Engl J Med. 2014;370:1583-1593
- Lamontagne F, Richards-Belle A, Thomas K, et al; 65 Trial Investigators. Effect of reduced exposure to vasopressors on 90-day mortality in older critically ill patients with vasodilatory hypotension. JAMA. 2020;323:938-949
- Russell JA, Walley KR, Singer J, et al; VASST Investigators. Vasopressin versus norepinephrine infusion in patients with septic shock. N Engl J Med. 2008;358:877-887
- Gordon AC, Mason AJ, Thirunavukkarasu N, et al. Early vasopressin versus norepinephrine in patients with septic shock (VANISH). JAMA. 2016;316:509-518
- Khanna A, English SW, Wang XS, et al. Angiotensin II for the treatment of vasodilatory shock (ATHOS-3). N Engl J Med. 2017;377:419-430
- Hernández G, Ospina-Tascón GA, Damiani LP, et al; ANDROMEDA-SHOCK Investigators. Resuscitation targeting peripheral perfusion vs lactate in septic shock. JAMA. 2019;321:654-664
- Zampieri FG, Damiani LP, Bakker J, et al. A Bayesian re-analysis of the ANDROMEDA-SHOCK trial. Am J Respir Crit Care Med. 2020;201:423-429
- Lara B, Enberg L, Ortega M, Leon P, Kripper C, Aguilera P, Kattan E, Castro R, Bakker J, Hernandez G. Capillary refill time during fluid resuscitation in patients with sepsis-related hyperlactatemia at the emergency department is related to mortality. PLoS One. 2017;12:e0188548
- ANDROMEDA-SHOCK-2 Investigators. Personalized haemodynamic resuscitation targeting capillary refill time in early septic shock (ANDROMEDA-SHOCK-2). JAMA. 2025; epublished Oct 29
- Kattan E, Bakker J, Estenssoro E, et al. Haemodynamic phenotype-based, capillary refill time-targeted resuscitation in early septic shock: study protocol (ANDROMEDA-SHOCK-2). Rev Bras Ter Intensiva. 2022;34:96-106
- Monnet X, Osman D, Ridel C, Lamia B, Richard C, Teboul J-L. Passive leg raising predicts fluid responsiveness in the critically ill. Crit Care Med. 2006;34:1402-1407
- Shoemaker WC, Appel PL, Kram HB, Waxman K, Lee TS. Prospective trial of supranormal values of survivors as therapeutic goals in high-risk surgical patients. Chest. 1988;94:1176-1186
- Hayes MA, Timmins AC, Yau EH, Palazzo M, Hinds CJ, Watson D. Elevation of systemic oxygen delivery in the treatment of critically ill patients. N Engl J Med. 1994;330:1717-1722
- Pocock SJ, Ariti CA, Collier TJ, Wang D. The win ratio: a new approach to the analysis of composite endpoints. Eur Heart J. 2012;33:176-182
- Pocock SJ, Stone GW. The primary outcome fails—what next? N Engl J Med. 2016;375:861-870
- Douglas IS, Alapat P, Corl K, et al. Randomized clinical trial of fluid responsiveness-guided resuscitation (FRESH). Chest. 2020;158:1431-1445
- STARRT-AKI Investigators. Timing of initiation of renal-replacement therapy in acute kidney injury. N Engl J Med. 2020;383:240-251
- Gaudry S, Hajage D, Schortgen F, et al. Initiation strategies for renal-replacement therapy in the ICU (AKIKI). N Engl J Med. 2016;375:122-133
- Barbar SD, Clere-Jehl R, Bourredjem A, et al. Timing of renal-replacement therapy in septic shock (IDEAL-ICU). N Engl J Med. 2018;379:1431-1442
- Girard TD, Kress JP, Fuchs BD, et al. Efficacy and safety of a paired sedation and ventilator weaning protocol (ABC trial). Lancet. 2008;371:126-134
- Olsen HT, Nedergaard HK, Strøm T, et al. Nonsedation or light sedation in critically ill, mechanically ventilated patients (NONSEDA). N Engl J Med. 2020;382:1103-1111
- ICU-ROX Investigators. Conservative oxygen therapy during mechanical ventilation in the ICU. N Engl J Med. 2020;382:989-998
Informal Bayesian Analysis using AI
The outline of the workings are shown in case AI has gotten it horribly wrong....
Using a non-informative (flat) prior and normal-likelihood approximations for each reported estimate, posterior probabilities were derived for the likelihood that outcomes favoured the CRT-PHR strategy. For mortality, the posterior is expressed on the risk-difference scale; for continuous outcomes, on the mean-difference scale (CRT-PHR minus usual care). Negative values favour CRT-PHR. The calculations assume independent, normally distributed sampling errors and are therefore illustrative rather than hierarchical Bayesian model outputs.
| Outcome | Estimated Difference (CRT-PHR − Usual Care) |
95% CI | Posterior Pr(benefit) | Interpretation |
|---|---|---|---|---|
| 28-day mortality | −0.1 % | (−4.6 to +4.4) | ≈ 0.52 | Essentially neutral – inconclusive |
| 90-day mortality | −1.0 % | (−5.8 to +3.7) | ≈ 0.66 | Modest, non-definitive probability of benefit |
| Vasopressor days | −0.95 days | (−1.58 to −0.34) | > 0.999 | Virtually certain reduction |
| Mechanical-ventilation days | −0.82 days | (−1.55 to −0.11) | ≈ 0.99 | Very high probability of fewer days |
| Renal-replacement-therapy days | −0.45 days | (−0.89 to −0.07) | ≈ 0.98 | Very high probability of fewer days |
| Composite “vital-support” days | −1.31 days | (−2.05 to −0.56) | > 0.999 | Virtually certain reduction |
Summary: Under flat priors, the posterior probability that CRT-PHR reduces mortality is ~52% at 28 days and ~66% at 90 days—statistically inconclusive. In contrast, the probabilities that CRT-PHR reduces durations of vasopressor use, mechanical ventilation, RRT and composite vital-support days are all >98%, indicating very strong probabilistic evidence of shorter organ-support times.
Assumptions (kept simple and explicit)
-
Binary outcomes (mortality): posterior on the risk difference (CRT-PHR − Usual care) is
( \Delta \sim \mathcal{N}(\hat{\Delta},, \mathrm{SE}^2) ) with
( \hat{\Delta} = \hat{p}\mathrm{CRT} - \hat{p}\mathrm{UC} ) and
( \mathrm{SE}^2 \approx \frac{\hat{p}\mathrm{CRT}(1-\hat{p}\mathrm{CRT})}{n_\mathrm{CRT}} + \frac{\hat{p}\mathrm{UC}(1-\hat{p}\mathrm{UC})}{n_\mathrm{UC}} ).
Non-informative prior on the difference ⇒ posterior is the normal approximation centred on the observed difference.
The posterior probability that CRT-PHR is better is ( \Pr(\Delta < 0) = \Phi!\big((0-\hat{\Delta})/\mathrm{SE}\big) ). -
Continuous outcomes (days): posterior on the mean difference (CRT-PHR − Usual care) is
( \Delta \sim \mathcal{N}(\hat{\Delta},, s_1^2/n_1 + s_0^2/n_0) ) using the reported SDs (s) and (n).
Again, ( \Pr(\Delta < 0) = \Phi!\big((0-\hat{\Delta})/\mathrm{SE}\big) ).
(\Phi) is the standard Normal CDF.
Mortality
28-day mortality (as requested for the composite)
-
CRT-PHR: 191/720 = 0.265
-
Usual care: 199/747 = 0.266
-
Risk difference ( \hat{\Delta} = -0.0010 )
-
( \mathrm{SE} \approx \sqrt{0.265(0.735)/720 + 0.266(0.734)/747} \approx 0.0231 )
-
Posterior ( \Pr(\Delta < 0) = \Phi!\big(0.0010/0.0231\big) = \Phi(0.043) \approx 0.52 )
Interpretation: With a flat prior and normal-likelihood, there’s ~52% posterior probability that 28-day mortality is lower with CRT-PHR — essentially equipoise.
90-day mortality (reported as a tertiary endpoint)
-
CRT-PHR: 231/719 = 0.321
-
Usual care: 247/744 = 0.332
-
Risk difference ( \hat{\Delta} = -0.0104 )
-
( \mathrm{SE} \approx \sqrt{0.321(0.679)/719 + 0.332(0.668)/744} \approx 0.0245 )
-
Posterior ( \Pr(\Delta < 0) = \Phi!\big(0.0104/0.0245\big) = \Phi(0.424) \approx 0.66 )
Interpretation: About 66% posterior probability that 90-day mortality is lower with CRT-PHR — modest, not decisive.
Duration endpoints (days to final cessation within 28 days)
All probabilities below are ( \Pr(\Delta < 0) ), i.e., probability the mean number of days is lower with CRT-PHR.
Vasopressor days
-
Means (SDs): 3.9 (4.5) vs 4.7 (5.5); ( n_1=720,; n_0=747 )
-
( \hat{\Delta} = -0.95 )
-
( \mathrm{SE} = \sqrt{4.5^2/720 + 5.5^2/747} \approx 0.262 )
-
Posterior ( \Pr(\Delta<0) = \Phi(0.95/0.262) = \Phi(3.63) \approx 0.9999 )
Mechanical-ventilation days
-
Means (SDs): 3.5 (6.1) vs 4.3 (7.3)
-
( \hat{\Delta} = -0.82 )
-
( \mathrm{SE} \approx \sqrt{6.1^2/720 + 7.3^2/747} \approx 0.350 )
-
( \Pr(\Delta<0) = \Phi(0.82/0.350) = \Phi(2.34) \approx 0.99 )
Renal-replacement-therapy days
-
Means (SDs): 0.9 (3.6) vs 1.4 (4.7)
-
( \hat{\Delta} = -0.45 )
-
( \mathrm{SE} \approx \sqrt{3.6^2/720 + 4.7^2/747} \approx 0.218 )
-
( \Pr(\Delta<0) = \Phi(0.45/0.218) = \Phi(2.06) \approx 0.98 )
Composite “vital-support days”
-
Means (SDs): 5.9 (6.2) vs 7.2 (7.6)
-
( \hat{\Delta} = -1.31 )
-
( \mathrm{SE} \approx \sqrt{6.2^2/720 + 7.6^2/747} \approx 0.362 )
-
( \Pr(\Delta<0) = \Phi(1.31/0.362) = \Phi(3.62) \approx 0.9999 )
Summary
Using weak (flat) priors and normal-likelihood posteriors, there is ~>99% probability of fewer vasopressor days and composite vital-support days, ~99% for fewer ventilation days, and ~98% for fewer RRT days with CRT-PHR.